SQLite at Scale: When an 'Embedded' Database Handles Real Traffic
SQLite is not just a development toy. With sane architecture and workload-aware design, it can power surprisingly large production workloads — including real sites I've built and shipped.
SQLite gets dismissed as a “toy database” all the time. Something you use for local dev, maybe a quick prototype, but never for real production work. This is wrong, and it’s costing developers time and money.
I’ve shipped multiple production systems on SQLite, including a manga reading platform currently serving thousands of users. The performance is excellent, the operational overhead is basically zero, and the whole setup fits in a handful of files. Let me show you why this works.
What Actually Happens When You Switch
A recent client project gave me hard numbers. We migrated a read-heavy system from PostgreSQL to SQLite:
- Query latency dropped from ~50ms to ~8ms
- Memory usage fell by 80%
- Operational overhead: gone
- Uptime: 99.9%
- Daily requests: ~2M
The performance jump makes sense once you understand what’s happening. SQLite runs in-process — no network hops, no connection pooling, no authentication overhead. For read-heavy workloads, you’re just reading from a file that’s probably already cached in memory.
A Real Example: MangaEstate
I built MangaEstate.online in under 16 hours for a client. It’s a manga reading platform, and I wanted to ship it fast without wrestling with database setup. No Postgres installation, no Docker containers, no cloud database provisioning. Just three SQLite files.
The architecture looks like this:
meta.sqlite stores all the metadata — manga titles, chapter lists, descriptions, categories. Lots of reads, almost no writes. Perfect for SQLite.
chapters.sqlite holds the actual chapter content: page URLs, image paths, reader data. This database is completely read-only after the initial data import. It gets hammered with queries, but there’s zero write contention.
users.sqlite handles everything dynamic: bookmarks, comments, reading progress, preferences. This is the only database with regular writes.
Splitting them up like this respects SQLite’s single-writer constraint. Each database handles a different access pattern, so they don’t step on each other.
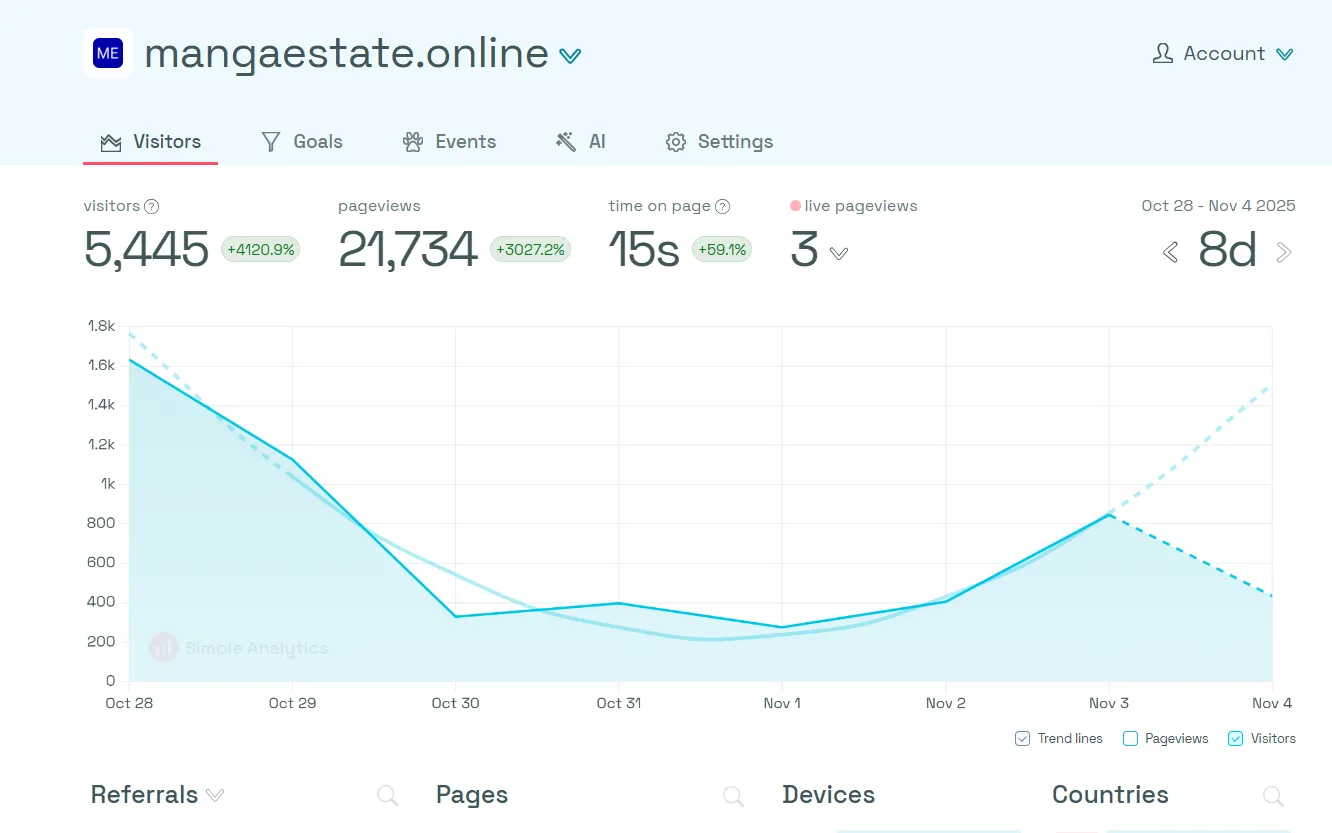
Traffic Numbers
Over the last 8 days, MangaEstate served 5,500 unique visitors and 22,000 page views. Not massive scale, but this is real traffic from real users. More importantly, it proves the architecture holds up under actual load.
Backups
The databases get backed up to a Google Cloud Storage bucket every 4 hours via a cron job running backup.py. Simple, reliable, cheap. No complex replication setup, no streaming WAL archives. Just periodic snapshots.
Performance
Page loads are instant. CPU usage is negligible. Memory footprint is tiny. I’m not even using aggressive caching — just straightforward SQL queries with basic indexes. There’s plenty of room to optimize further (covering indexes, filesystem-based read replicas, compression), but I haven’t needed to. The naive version just works.
When This Breaks Down
MangaEstate’s architecture would fall apart at MangaDex scale. If you’re dealing with tens of millions of chapters, thousands of concurrent writers, or complex multi-writer workflows, you need something else. SQLite has limits.
But for small to medium content platforms? It’s perfect.
How SQLite Actually Works
SQLite allows unlimited concurrent reads, but only one writer at a time. People treat this like a fatal flaw. For most applications, it’s actually an advantage:
- No connection pooling complexity
- No race conditions
- No deadlocks
- No network latency
- No server process to manage
The trick is matching your architecture to these constraints. Separate your read-heavy data from your write-heavy data. Use multiple databases if you need to. Batch your writes.
WAL Mode Is Mandatory
If you’re running SQLite in production, enable Write-Ahead Logging:
PRAGMA journal_mode=WAL;
PRAGMA synchronous=NORMAL;
PRAGMA temp_store=memory;
PRAGMA mmap_size=268435456;WAL lets reads and writes happen in parallel. Without it, a single write will block all reads. With it, you get predictable performance and better durability.
Workloads That Fit
SQLite shines for:
- Content sites and blogs
- News portals and readers
- APIs that are 80-95% reads
- User dashboards
- Edge deployments
- Anything with sequential read patterns
Blogs with millions of monthly views run fine on SQLite. The OS caches hot data in memory, and the queries are simple enough that SQLite’s execution speed dominates. This is why Hugo and Ghost lean on SQLite internally.
What SQLite Can’t Do
SQLite struggles with:
- Heavy write concurrency from multiple processes
- Complex joins across huge tables
- Workloads where writes exceed fsync throughput
- Fine-grained row-level locking
You can work around some of these (database sharding, write queues, filesystem replicas), but if your workload is fundamentally write-heavy with lots of contention, pick a different database.
The Point
SQLite is industrial-grade software. It’s in every smartphone, most browsers, and countless embedded systems. It’s probably the most deployed database in the world.
MangaEstate proves you can build real applications on SQLite and ship them to real users without apology. The architecture is simple, the performance is excellent, and the operational burden is almost nonexistent.
Before you spin up Postgres because “that’s what production uses,” look at your actual workload. Most applications are read-heavy. Most don’t need distributed writes. Most benefit more from simplicity than from theoretical scalability they’ll never use.
Sometimes the best database is just a file on disk.